by Weston Pace
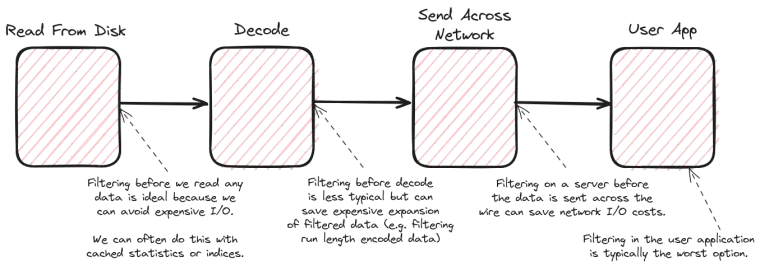
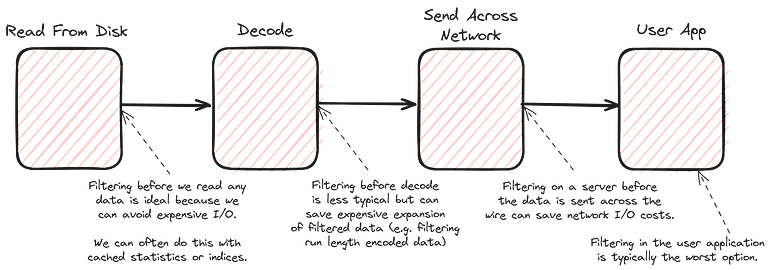
Filter pushdown is one of the more fundamental optimizations in any data engineering pipeline. The premise is simple: the earlier you filter data in your pipeline the less work you have to do overall.
Unfortunately, as data solutions become more decentralized, this optimization has become more difficult because it requires many different components to agree on what a “filter expression” is. Here at LanceDb we want Lance to serve as an efficient data source in as many situations as possible. This means we’ve run head first into this problem.
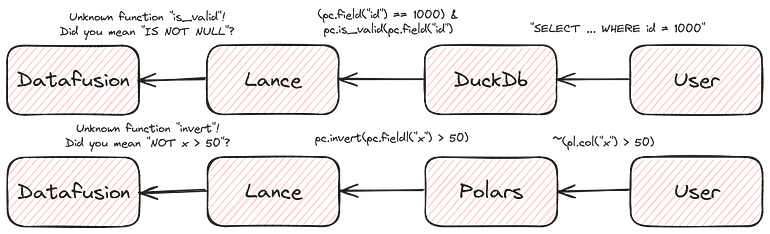
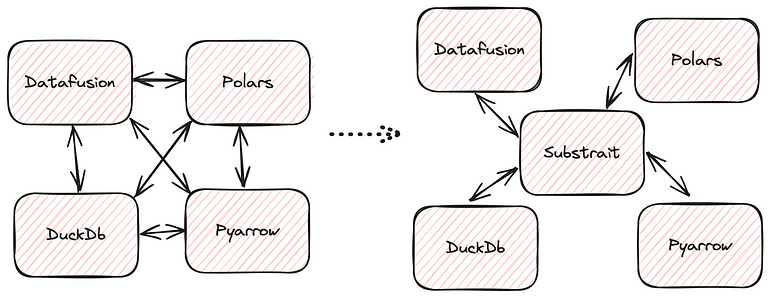
Between Datafusion, Lance, DuckDb, Pyarrow, and Polars we have four different representations of filters (not five, since Lance uses Datafusion internally)! We talked about this problem briefly in the past when discussing our Polars integration. We’ve also been maintaining a lot of custom code to handle this scenario in our DuckDb integration. If our solution to this problem is to simply add conversion methods between the different libraries then we’re going to need O(n²) different converters and we’re just getting started!
Substrait to the Rescue
Fortunately, using Substrait, we’ve managed to find a more maintainable solution. Substrait is an open standard for query plans and, since expressions are a part of query plans, it gives us an open standard for compute expressions too. Support for Substrait has been growing over past year and both pyarrow and Datafusion now support converting expressions to and from Substrait. In a recent release of Lance we added support for accepting filter expressions as Substrait and it’s now used internally to support our pushdown from pyarrow, duckdb, and polars, which allows us to retire our custom conversion logic.
What’s Next?
By simplifying our code this feature is a win on its own. However, we believe the future of Substrait is bright and its potential has just begun to show. Let me describe a few of the potential developments that we’ve got our eye on.

More Complex Pushdown
Filter pushdown has been historically limited to some very basic compute operations such as <, ≤, >, ≥, ==, … There’s even a special word, “sargable”, used to refer to these expressions. This limitation originates from the fact that these are the only expressions that are easily pushed down into classic database indices (e.g. btrees).
Unfortunately, this limitation is becoming too restrictive. Pushdown needs to be able to cross many different boundaries, and the underlying systems can sometimes support much richer and more complex functions. For example, Skyhook is a compelling demonstration where arrow-cpp (with all arrow compute functions) is installed in the storage nodes of a Ceph cluster. Imagine a cloud storage API like S3-select except it can apply rich complex filters before sending Arrow data outside the cloud.
Alignment on Function Behavior
Substrait integrations have so far been focused on properly mapping “function names”. For example, as shown above, Pyarrow has a scalar function “invert” which, in Datafusion, is not a scalar function but actually a syntax node “not”. In Substrait these are both a scalar function named “not” and so, by using Substrait, the two libraries can find common ground. This is kind of mapping is required but also fairly basic.
A more complicated challenge is aligning function behavior between different libraries, especially when it comes to corner cases. For example, should integer division by zero yield NULL or raise an error? What should happen if there is an arithmetic overflow with unsigned integers? How should negative numbers be handled in the modulus operation? In Substrait, we know that forcing libraries to adopt one single behavior isn’t going to work.

Instead, the preferred approach is to list all of the different behaviors, typically using “function options”. Adoption of these options has been slow so far. Most Substrait consumers simply ignore them. However, efforts such as the BFT (which aims to document all these subtle differences) should at least make it possible for users to know when (and how) a query will behave differently as the backend changes and this can eventually drive adoption of the feature in plan consumers.
“Plan Pushdown”, Going Beyond Filters
Earlier we pointed out that data endpoints can handle complex expressions. It turns out that some, such as Lance, can handle pushing down even more complicated plan optimizations that don’t fit the template of “filter pushdown”. One of Lance’s most powerful features is its secondary vector indices. Applying a vector index is more than a simple filter pushdown.
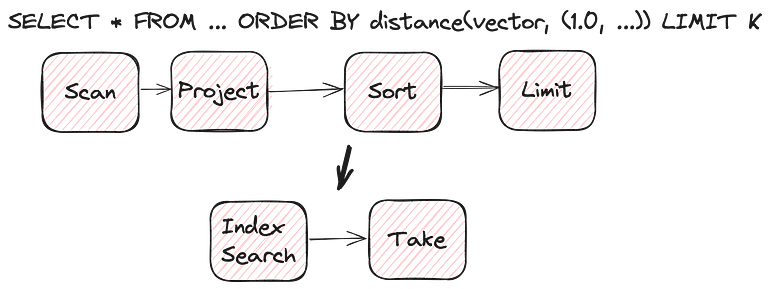
How should DuckDb or Polars push something like this down? Currently, the Lance integration with these libraries is limited to pushing down filters. If you want to perform vector searches then you need to use Lance directly (for now). We could invent a new concept for “vector search pushdown” or, using Substrait, we could simply pass the entire query plan down to the data source and let it optimize the query however it sees fit.
Admittedly, the ecosystem isn’t quite ready for this feature yet. Consumers would have to considerable investment to involve something like this in their planning process. However, it is an exciting look at the kinds of things that could become possible as Substrait adoption grows and it’s one of the reasons that Lance is excited to add these Substrait integrations whenever possible.