
In this short blog post we’ll take you through some simple benchmarks to show the random access performance of Lance format.
Lance delivers comparable scan performance to parquet but supports fast random access, making it perfect for:
- search engines
- real-time feature retrieval, and
- speeding up shuffling performance for deep learning training
What makes Lance interesting is that in the existing tooling ecosystem you either have to deal with the complexity of putting together multiple systems OR dealing with the expense of all in-memory stores. Moreover, Lance doesn’t require extra servers or complicated setup. pip install pylance is all you need.
Test setup
Here we’re going to compare the random access performance of Lance vs parquet. We’ll create 100 million records where each value is a 1000-character long randomly generated string. We then run a benchmark of 1000 queries that fetch a random set of 20–50 rows across the dataset. Both tests are done on the same Ubuntu 22.04 system:
sudo lshw -short
Class Description
=============================================================
system 20M9CTO1WW (LENOVO_MT_20M9_BU_Think_FM_ThinkPad P52)
memory 128GiB System Memory
memory 32GiB SODIMM DDR4 Synchronous 2667 MHz (0.4 ns)
memory 32GiB SODIMM DDR4 Synchronous 2667 MHz (0.4 ns)
memory 32GiB SODIMM DDR4 Synchronous 2667 MHz (0.4 ns)
memory 32GiB SODIMM DDR4 Synchronous 2667 MHz (0.4 ns)
memory 384KiB L1 cache
memory 1536KiB L2 cache
memory 12MiB L3 cache
processor Intel(R) Xeon(R) E-2176M CPU @ 2.70GHz
storage Samsung SSD 980 PRO 2TBCreating dataset
To run this benchmark we first generate 100 million entries, each of which is a 1000 character long string.
import lance
import pyarrow as pa
import random
import string
batch_size = 1_000_000
for i in range(100):
print(f"Creating batch {i}")
string_arr = pa.array([''.join(random.choices(string.ascii_letters, k=1_000))
for _ in range(batch_size)])
tbl = pa.Table.from_arrays([string_arr], names=["value"])
print(f"Writing batch {i} to lance")
if i == 0:
params = {"mode": "create"}
else:
params = {"mode": "append"}
lance.write_dataset(tbl, "take.lance", **params)Converting from Lance to parquet is just one line:
pa.dataset.write_dataset(lance_dataset.scanner().to_reader(),
"take.parquet",
format="parquet")Benchmarking Take
For both datasets, we run 1000 queries each. For each query, we generate 20–50 row id’s randomly and then retrieve those rows and record the run time. We then compute the average time per key.
The API we use is Dataset.take:
import time
tot_time = 0
tot_keys = 0
nruns = 1000
ds = lance.dataset("take.lance")
for _ in range(nruns):
nrows = np.random.randint(20, 50, 1)
row_ids = np.random.randint(0, 100_000_000, nrows)
start = time.time()
tbl = ds.take(row_ids)
end = time.time()
tot_time += end - start
tot_keys += len(row_ids)
print(f"Lance: mean time per key is {tot_time / tot_keys}")The parquet snippet is almost identical, so it’s omitted.
Here’s the output (in seconds):
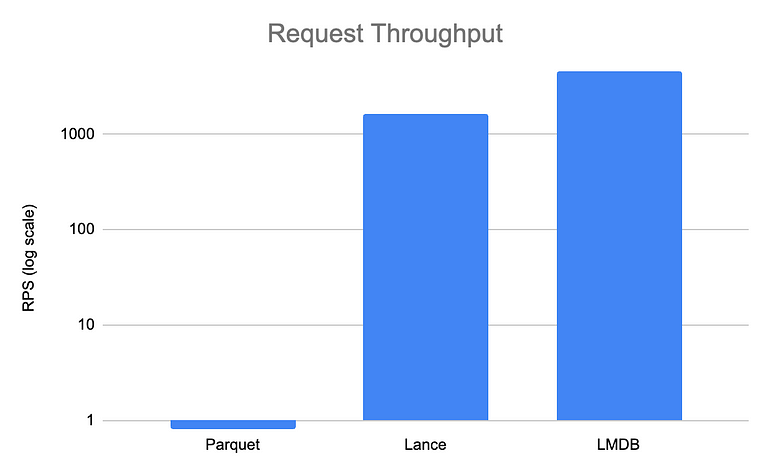
Lance: mean time per key is 0.0006225714343229975
Parquet: mean time per key is 1.246656603929473I also benchmarked a similar setup using LMDB and plotted all on the same chart for comparison:
Key lookup
If you’ve noticed we’ve only benchmarked Dataset::Take on row ids. On the roadmap is to make this more generic so you can lookup arbitrary keys in any column.
Part of the limitation is in Lance itself. Currently looking up a particular key is done using a pyarrow Compute Expression, like dataset.to_table(columns=["value"], filter=pa.Field("key") == <key>) . Currently this requires scanning through the key column to find the right row ids, which adds more than 10ms to the query time. To solve this problem, we plan to 1) calculate batch stats so we can 2) implement batch pruning. And for super heavily queried key columns, 3) adding a secondary index would make arbitrary key lookups much faster.
Duckdb integration
In Python, Lance is already queryable by DuckDB via the Arrow integration. However, one major shortcoming of DuckDB’s Arrow integration is the extremely limited filter pushdown. For example, pa.Field("key") == <key> is pushed down across the pyarrow interface, but multiple key lookups is not. This can be the difference between <10ms response time vs >500ms response time. In Lance OSS, we’re working on a native duckdb extension so that we don’t have to be subject to these limitations.
Conclusion
We’ve been claiming 100x faster random access performance than parquet, but as this benchmark shows, it’s really more like 2000x. Lance brings fast random access performance to the OSS data ecosystem needed by important ML workflows. This is critical for search, feature hydration, and shuffling for training deep learning models. While Lance’s performance is already very valuable for these use cases, we’ll be working to implement generalized key lookups, better duckdb integration, and hooks to distribute large Lance datasets across Spark/Ray nodes.
If any of these use cases apply to you, please give Lance a shot. We’d love to hear your feedback. If you like us, please give us a ⭐ on ️Github!