by Will Jones
In Lance v0.8.21, we introduced column statistics and statistics-based page pruning. This enhancement reduces the number of IO calls needed for scanning with a filter, making scans 30x faster in some cases. This is a common optimization in analytics formats like Parquet. However, combined with Lance’s superior handling of vector and unstructured data, we get 3x faster scans with predicates for vector data versus Parquet.
Today these statistics are used when scanning datasets or deleting data based on a predicate. This is the first of several improvements we’ll be making to filtering, so expect to see similar improvements for vector search pre-filtering.
Performance improvements for scans
How much does this feature improve performance? As a simple example, we created a test dataset with 1 million rows. The data had the schema:
- id: an int64 incrementing id
- score: a random float32
- category: a string column with random letter of the alphabet
- embedding: a 1536-dimensional vector
To maximize the impact of statistics-based pruning, we ran the generated dataset through Delta Lake’s Z-order to cluster on the score and category columns. We wrote this out as a Parquet dataset (using PyArrow 14.0.1) and Lance dataset. On disk Parquet took 7.1 GB and Lance took 6.5 GB.
We ran two queries with the same filter but different projections. One we call “scalar” as it projects id and score, two analytical columns. Another we call “vector”, as it projects id and embedding, the latter being a vector column. The filter predicate in both cases is score > 0.8 AND category IN (‘A’, ‘B', ‘C').
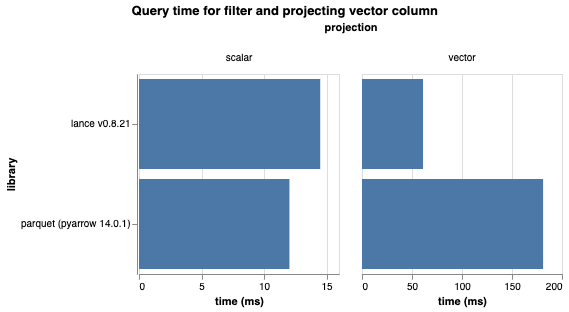
When filtering on score and category and projecting the id and embedding columns, Lance achieved a significant performance improvement. It was 30 times faster than before and surpassed the performance of Parquet scan by a factor of 2.8. This improvement is attributed to the new scanner that reduced the amount of data that needed to be loaded. In earlier versions of Lance, running this query required 10,248 IO calls, but with stats-based pruning, only 538 IO calls were needed. That’s a 94% reduction in IO!

As expected, Lance outperforms Parquet when selecting vector columns. However, what about scalar columns? We also executed the same query, but only projected id and score. In this case, Lance's query time improved by 3x compared to previous versions, and it was only about 3 ms slower than Parquet. While Parquet excels in analytics data, we are confident that we can make additional optimizations to match or even surpass Parquet's performance.
How we prune pages
Lance uses an expression simplification approach to statistics based page pruning. This is different from other systems which can only prune entire sets of rows. There are two additional things we can do:
- Eliminate reading some filter columns, if they are no longer needed
- Create residual expressions, which is the remaining predicate that must be evaluated given what we know in the statistics.
To see how this works, we can image an example. Say we have two columns: score, a float column, and category, a string column. For simplicity, let’s say these are both not nullable. We want to filter for where score > 0.5 AND category IN ('A', 'B', 'C'). Data is organized into groups of rows, where each group has 1 page for each of the columns. As we are scanning, we have statistics about min and max bounds for both score and category.
In the first page, max(score) = 0.4 we know for sure that this group cannot satisfy the score > 0.5. Anything AND’ed with false is going to be false, so this filter isn’t satisfiable by this entire group. We can skip it.
In the second page, min(score) = 0.6 so we know for certain all rows will satisfy the score > 0.5. Any expression AND’ed with true is the same as the original expression, so we can simplify the predicate to category IN ('A', 'B', 'C'). This predicate doesn’t involve the score column, so we can skip reading that column and just read category in order to evaluate this expression.
In the third page, min(category) = 'D', so we know category IN (...) is always false. Similar to the first page, this eliminates the entire group.
In the fourth and final page, min(category) = 'C'. This doesn’t eliminate the category filter, but it does allow us to simplify it to the residual expression category = 'C', since 'A' and 'B' are no longer possibilities in this page.
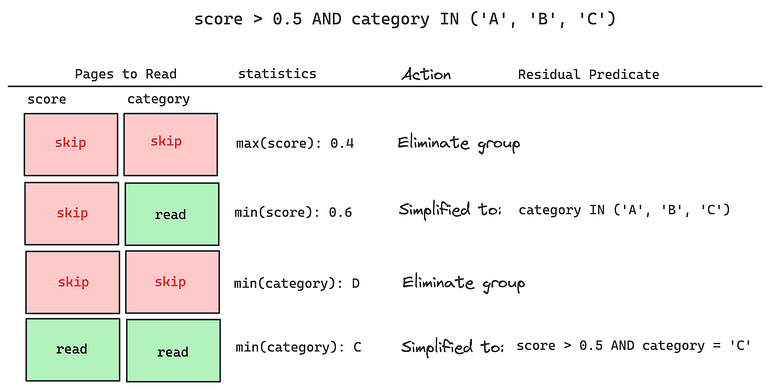
By performing these simplifications, we only needed to read 3 of the 8 pages of data. Additionally, in one of the cases we were able to simplify the filter to an equality check rather than set containment check, which is generally cheaper.
Implementing with DataFusion
Lance’s scanner uses DataFusion, a toolbox for creating query engines. We utilize this library for SQL parsing, query planning, expression optimization, and execution. Implementing this feature required two steps:
- Rewriting expressions based on statistics. For example, if the earlier expression was
score > 0.5 AND category IN ('A', 'B', 'C')and the statistic wasmax(score) = 0.4, it would be rewritten asfalse AND category IN ('A', 'B', 'C'). - Simplifying expressions. In this case,
false AND category IN ('A', 'B', 'C')would be simplified tofalse. These simplifications are based on the expression itself and general rules.
We contributed the first step to DataFusion (PR). Right now this handles inequalities, null checks (IS [NOT] NULL), and IS IN, but could be extended to support more expression types in the future. The second step already had a high-quality implementation from other members of the DataFusion community.
Overall, our experience with DataFusion has been great. Many of the advanced features we look for have already been implemented, and those that we needed to implement got quick feedback and approval.
What’s next
These statistics are only useful to the extent the rows in your dataset are clustered for the columns are you are filtering on. Some tables will have a natural clustering based on insertion order. For example, if there is a insertion timestamp column or an incrementing id, those will already be ordered well and filtering on them will be very effective. In other cases, your data may need to be rearranged to be optimally clustered. We already have a compaction operation that requires moving your data, so during that phase we could optionally cluster data along columns of your choice. This is the first enhancement that is on our roadmap.
In addition, most table formats have some statistics at the file level in addition to the page-level. This allows skipping entire files that don’t have relevant data. This is especially helpful for cold queries where the statistics haven’t already been cached. This feature is also on our roadmap.
Finally, there are several other query types where we can integrate statistics. For example, they can be used during the pre-filtering stage of vector search to improve the performance of ANN queries that have metadata filters.
Statistics unlocks a variety of scenarios where performance can be significantly improved. All of these improvements are on our roadmap and will help make Lance the best format for AI data lakes.