Building a Super Agent with OpenAI-Compatible Technologies
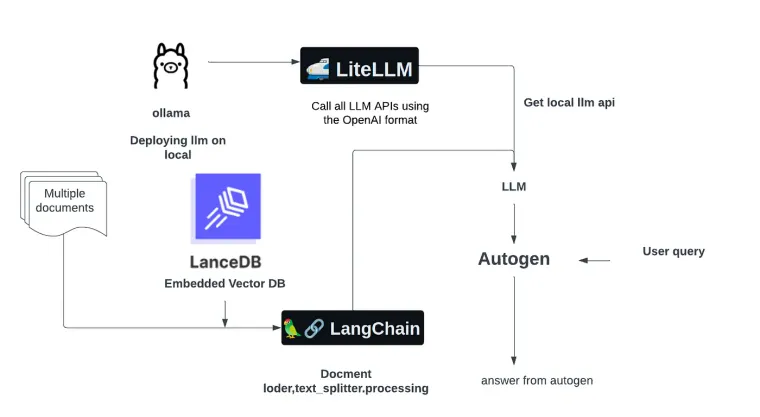
In the rapidly evolving field of AI, integrating large language models (LLMs) into local systems and applications has become a pivotal step toward creating more dynamic and responsive AI agents. This blog post will guide you through setting up a “Super Agent” by leveraging the capabilities of Ollama, Litellm, Autogen, LangChain, and LanceDB. We aim to create an AI that can understand and process information from a PDF, providing knowledgeable responses to related queries.
Getting Started with Ollama
Ollama makes running large language models locally on your system feasible, even if you only have a CPU. To get started, you’ll need to install Ollama using pip:
pip install ollamaFollowing the installation, delve into the diverse array of models accessible through the Ollama’s Library. For our specific project, we’ll be utilizing the Mistral model. However, don’t hesitate to conduct experiments with alternative models. To seamlessly incorporate Mistral into your local environment, execute the following commands:
ollama pull mistral # download the mistral latest model
ollama run mistral # run modelRunning the command makes the Mistral model start working, letting you ask it questions directly on your computer. This first step shows how Ollama helps you use big language models on your computer. Later on, we’ll use Ollama’s endpoint in Autogen.

Integrating LiteLLM for API Flexibility
Using LiteLLM is like adding a helpful tool that lets Autogen easily connect with different LLM APIs, such as Ollama, using a standard format from OpenAI. This connection is important for our project because it provides Autogen with the necessary way to communicate with these APIs. To get LiteLLM set up on your system, simply run this command:
pip install litellmAnd then, start the LiteLLM API to interface with the Ollama/Mistral model:
litellm -model ollama/mistralThis command activates the LiteLLM API on port 8000, making it ready for use. This setup is a game-changer for developers looking to integrate large language model functionalities into their applications.

Setting Up Autogen for Interactive Agents
Autogen is a crucial player in conversational AI, enabling the development of sophisticated applications that can handle complex conversations far beyond simple questions and answers. It’s designed to build agents that can engage in detailed discussions, not just with humans but also among themselves, to tackle intricate challenges easily.
Our project leverages Autogen to power a Super Agent, designed to sift through and understand content from a specific source, such as a food PDF. By integrating Autogen, our Super Agent can parse the PDF content efficiently, ensuring users receive precise and knowledgeable answers. This improves the quality of interactions and highlights conversational AI's real-world utility in extracting and leveraging information from targeted content.
Leveraging LangChain for Contextual Awareness
LangChain provides a powerful toolkit of libraries, templates, and tools that help applications understand and act on user queries within their specific contexts. This understanding is essential for any application that aims to grasp the subtleties of user requests.
By incorporating LangChain, our Super Agent becomes even more adept. It connects with a vector store, LanceDB, to efficiently find answers within food PDF content. This boosts the accuracy of the responses and demonstrates how AI, combined with vector databases, can offer deep contextual insights and quick, precise answers.
Integrating LanceDB with Autogen for Efficient Data Management
LanceDB is a vector database designed for developers, offering a scalable solution to manage data effectively. In our project, we use LanceDB to index a food PDF, creating a searchable vector store. This store is essential for efficiently handling queries related to the food content.
Implementation Steps for Food Query Processing
- Vector Store Creation: We start by indexing the food PDF with LanceDB. This step converts the document into a vector store, making it searchable and ready for queries.
- LangChain Setup: Next, we use LangChain to implement a QA (Question-Answer) chain that utilizes the vector store for context. This enables the application to understand and respond to food-related questions accurately.
- Answer Function Development: The answer_food_question function is the heart of our application. It processes user questions through the QA chain, pulling relevant answers from the vector store.
- Autogen Agents Integration: We configure user and assistant agents in Autogen, allowing for dynamic interactions. These agents facilitate the function calls, making the conversation flow naturally and informatively about the food content.
The first step in the coding process involves downloading the necessary food PDF.
!wget https://pdf.usaid.gov/pdf_docs/PA00TBCT.pdf
load the embedding & LanceDB for storing information
By leveraging LangChain, we enable querying PDF documents directly through the ConversationalRetrievalChain
We are developing a function below, enabling the agent to retrieve answers to food-related questions efficiently
We are now at the stage of specifying the LLM configuration. Within this configuration, it’s essential to define both the functions and their corresponding descriptions. Please note that this configuration can be adjusted according to your specific requirements
As we approach the final step, it’s crucial to configure both an Autogen user agent and an assistant agent. This setup will facilitate dynamic interaction by enabling function calls within the agents.

Explore our Google Colaboratory notebook to see the integration of our agent with LanceDB in action.
Conclusion
Our project showcases the integration of Autogen, LiteLLM, Ollama, and LanceDB to create an AI agent capable of sophisticated interactions with data. Here’s a concise summary:
- Autogen Integration: Simplifies function calling, mirroring OpenAI’s ease of use.
- LiteLLM and Ollama Use: These tools allow our agent to run large language models efficiently.
- LanceDB Utilization: This enables our agent to interact directly with document data through a vector database.
- Enhanced Data Interaction: Our setup transforms data interaction, making complex information more accessible and manageable.
For further such projects, visit the vector-recipes repository for practical examples and ideas for your projects. This journey exemplifies how combining these technologies can revolutionize AI applications.